


Table of contents
- The Innovative Concept Behind Kubernetes
- Moving from Monolithic Applications to Microservice Applications
- Introducing Container Technologies
- Benefits of using Containers over VMs
- What is Kubernetes?
- Understanding Kubernetes Architecture
- How to Run an Application in Kubernetes
- Benefits of using Kubernetes
- Conclusion
Short Introduction: Ever since the high demand for the use of containers for packaging applications by developers. there has been a need for a container management system. In 2014 a team of Google developers came together to create a container management system called Kubernetes, also known as K8S. Kubernetes was accepted to Cloud-Native Computing Foundation (CNCF) in 2014 as an open-source tool. In this article, I will be discussing the nitty-gritty of the use case of Kubernetes as a container orchestration tool, the innovative concept behind it, its benefits, and also its components.
First of all, I will be talking about the innovative concept of how Kubernetes came about as a container management system and container orchestrating tool.
The Innovative Concept Behind Kubernetes
Moving from Monolithic Applications to Microservice Applications
Before the creation of Kubernetes, Developers bundle their applications into large components called monolithic applications. What is a monolithic application?
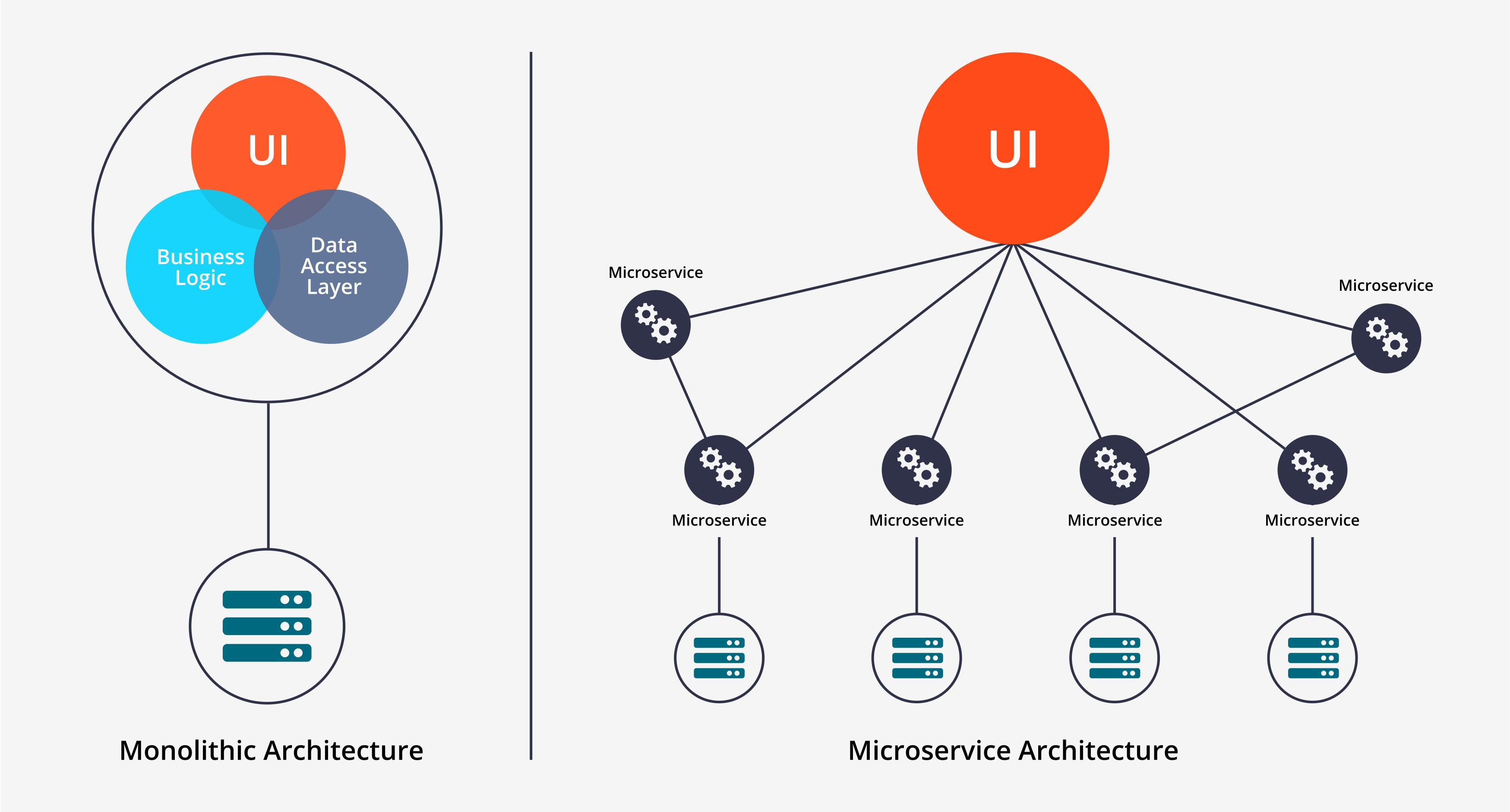 Monolithic applications are application components that are coupled together and managed as a simple entity. When changes are made in any part of the monolithic application, developers will constantly redeploy the whole monolithic application every time changes are being made, and this will lead to quality deterioration of the whole system application, and this is as well too daunting to do every time. Another drawback of a monolithic application is, In cases when a part of a monolithic application isn't scalable, developers can't scale the whole application. And this is where the concept of microservice applications came into play.
Monolithic applications are application components that are coupled together and managed as a simple entity. When changes are made in any part of the monolithic application, developers will constantly redeploy the whole monolithic application every time changes are being made, and this will lead to quality deterioration of the whole system application, and this is as well too daunting to do every time. Another drawback of a monolithic application is, In cases when a part of a monolithic application isn't scalable, developers can't scale the whole application. And this is where the concept of microservice applications came into play.
Microservice applications are applications that are separated into smaller independently deployable components. These components connect with each other through an API. So when developers are developing and deploying a microservice application separately, and changes are being made to one part of the application, developers don't need to redeploy the whole application, provided the API doesn't change. When it comes to scaling microservice applications, developers only scale the part of the application that needs it, unlike a monolithic application that requires developers to scale the whole application. But Microservice applications have their own drawback in cases when we have multiple components of the application, the components are prone to errors and it becomes too tedious to debug. tracing errors in the application and deploying the components becomes too tedious to carry out.
Introducing Container Technologies
Because of the drawbacks of both microservice applications and monolithic applications, there came the innovation of Container technologies. But before we get into the nitty-gritty of what containers are, we need to know what is a Virtual Machine (VM).
A VM is a compute resource that uses software instead of a physical computer to run programs and deploy apps. The way the VM works in an application is that developers dedicate a VM for each of the components of the application and also isolate their environment by providing each of them with operating system instances. But when the application starts having multiple components it becomes quite difficult to provide all the components with hardware resources, and also we will likely also want to manage and configure each of the VMs individually which is also going to be quite challenging for the application administrators to configure and manage all VMs. So instead of using VMs to isolate the environments of each microservice application, developers use container technologies. They allow you to run multiple services on the same host machine, while not only exposing a different environment to each of them, but also isolating them from each other, similarly to VMs, but with much less overhead.
Benefits of using Containers over VMs
Compared to VMs, containers are much more lightweight that allows you to easily run higher numbers of software components on the same hardware infrastructure, mainly because each VM needs to run its own set of system processes, which requires additional compute resources like CPUs, physical network cards, disk controllers, etc. Containers are a streamlined way to build, test, deploy and redeploy applications in multiple environments from a developer's local machine to an on-premises data center and even to the cloud. Containers help to increase application portability and reduce application overhead because they don't include operating system images. Now that we fully know what containers are let's get into the nitty-gritty of what Kubernetes is.
What is Kubernetes?
 Kubernetes is a portable, extensible, open-source platform for managing containerized workloads and services, that facilitates both declarative configuration and automation, developed by Google.
Basically, Kubernetes is a software system that allows developers to deploy, scale and manage their containerized applications.
Kubernetes is a portable, extensible, open-source platform for managing containerized workloads and services, that facilitates both declarative configuration and automation, developed by Google.
Basically, Kubernetes is a software system that allows developers to deploy, scale and manage their containerized applications.
Understanding Kubernetes Architecture
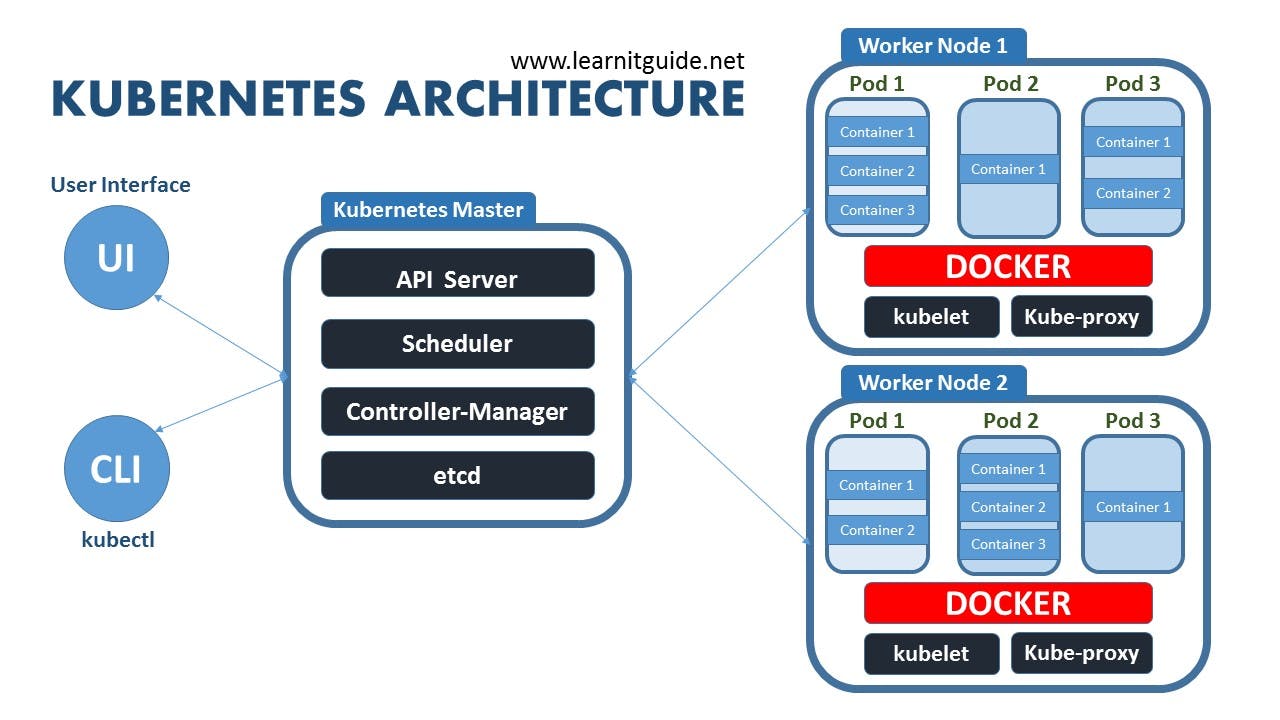 Kubernetes cluster is composed mainly of two types of nodes.
Kubernetes cluster is composed mainly of two types of nodes.
The Master Node
The Worker Node
The Master Node hosts Kubernetes Control Plane. The Control Plane controls and manages the whole Kubernetes system. It consists of components such as Kubernetes API Server, Scheduler, Controller Manager, and etcd. The Control Plane components control the state of the cluster and not the containerized applications. This is done by the worker node.
The Worker Node as the name means, they are the workload that runs the containerized applications. It also consists of components that carry out the task of providing services to containerized applications. They are Container runtime (e.g Docker, containerd, runC), Kubelet, Kubernetes Service Proxy (Kube-proxy).
The Master Node Components
The API Server: This acts as a gatekeeper or serves as authentication to access the Kubernetes cluster. it sends requests on any update and queries to the cluster either through a graphical user interface(GUI) or a command line.
The Scheduler: It schedules pods to the worker node or decides on which worker node pods should run on. This is after The Kubernetes API Server has validated the request to access the cluster.
The Control Manager: It keeps track of changes that are being made in the worker node. In cases where a pod dies, it makes a request to the scheduler, then the scheduler decides based on the resource calculation which node should restart the pod and then the scheduler makes a request to the Kubelet to restart the node.
Etcd: It is the key-value storage of the cluster state, processes and configuration. it also serves as the cluster brain, because the control manager and scheduler all work based on its data. Note that it doesn't store the application data nor acts as the application database.
The Worker Node Components
Kubelet: It talks to the API Server and manages containers on its node. Kubelet starts pods with a container and assigns resources from the node to the container, like CPU and RAM resources.
Container Runtime: It is a software that runs and manages components required to run containers. Container Runtime needs to be installed into each node in the cluster so that containers can run there. examples of Container Runtimeare Docker, cri-o, and containerd.
The Kubernetes Service proxy(Kube-proxy): Kube-proxy is responsible for forwarding requests from services to pods. Kube-proxy is installed on all nodes, which allows communication between pods and nodes to work with less overhead performance. In a scenario a pod is making a request to a database instead of service forwarding requests randomly to any replica of pods, Kube-proxy will correctly forward the request to the pod that initiated the request. Thus avoiding the network overhead of sending the request to the wrong pod.
Workload Objects There are some workload objects that make running containers in the Kubernetes cluster easy.
Pods: Pods are the smallest or basic unit of the Kubernetes cluster and also an abstraction of containers. Multiple containers can run on a pod. Pods are ephemeral and each pod has its unique IP address. Once a pod dies, Kubernetes creates a new pod and a new IP address is assigned to it. but this isn't appropriate, in cases when we are using the old IP address to communicate to a database. so services came into play.
Services: It has a permanent IP address that can be attached to each pod. The lifecycle of pods and services is not connected. Services expose our application to the end-user. It also serves as a load-balancer i.e when a pod crashes it forward requests to the less busy pod.
Deployment: Deployment is a blueprint or template where developers declare instructions about tasks the cluster needs to carry out. for example, Deployment is used to create a pod. Instructions are written in either YAML or JSON format. In practice, developers would most likely work with deployment than pods by specifying the number of pods in the YAML or JSON file. like I said earlier pods are a layer of abstraction of containers while deployment is also a layer of abstraction of pods.
Example of what a deployment looks like.
How to Run an Application in Kubernetes
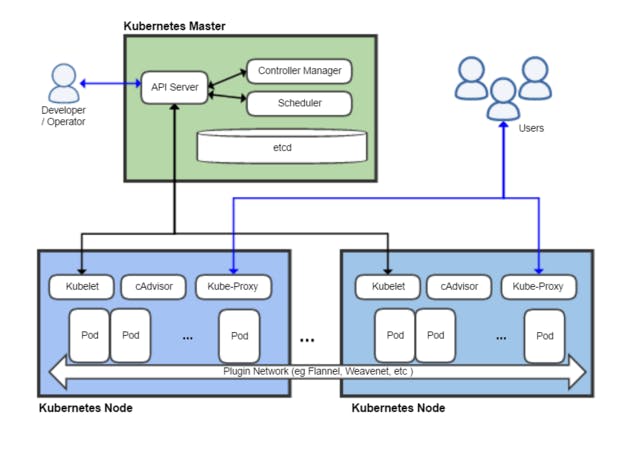 First of all, developers need to package their application written in any programming language of their choice into one or more container
images and push the images into any image registry. e.g Docker, and then write a description i.e a deployment of the application to Kubernetes API Server.
The deployment includes information such as the container image or images, that contains your application component, how those components are related to one another and which one needs to be run together on the same node, and which one doesn't need to. Also for each component, you can also specify the number of copies or replicas you want to run. In addition, the deployment also includes components that provide services to internal(within the components) and external clients and should be exposed via a single IP address and made available to other components and to the end-user of the application.
First of all, developers need to package their application written in any programming language of their choice into one or more container
images and push the images into any image registry. e.g Docker, and then write a description i.e a deployment of the application to Kubernetes API Server.
The deployment includes information such as the container image or images, that contains your application component, how those components are related to one another and which one needs to be run together on the same node, and which one doesn't need to. Also for each component, you can also specify the number of copies or replicas you want to run. In addition, the deployment also includes components that provide services to internal(within the components) and external clients and should be exposed via a single IP address and made available to other components and to the end-user of the application.
Benefits of using Kubernetes
Health Checking and Self Healing: Kubernetes helps to monitor deployed application components and nodes they run on and automatically reschedules them to other nodes in cases of a node failure.
Automatically Scaling: Kubernetes monitors application resources and automatically scales the whole cluster size up or down based on the needs of deployed applications.
Automatically Rollouts and Rollbacks: If changes are being made to an application and something goes wrong, Kubernetes will roll back to the previous version of the application.
High Availability: Kubernetes provide applications with high availability by making the application accessible anytime with no downtime.
Runs Everywhere: Since Kubernetes is an open-source tool it can run on on-premises, hybrid, and public cloud environments.
Conclusion
So far, a lot of large companies have been adopting Kubernetes into their application infrastructures, and so far it has been of help in optimizing IT costs and helping both the software engineering team and the operation team to carry out challenging tasks and reduce the development and the release timeframe of the application. Google so far has been supporting Kubernetes development by donating $3M to Cloud-Native Computing Foundation (CNCF) yearly. This is safe to say Kubernetes technology is here to stay.
In subsequent articles, I will be writing practically on how to run an application in Kubernetes. Kindly follow me for more related articles on DevOps and Cloud technologies. You can as well read about 15-kubernetes-best-practices by spacelift. Likes and comments are very much appreciated. connect with me via Linkedin
If you found the article quite beneficial, you can buy me a cup of coffee via this link buy-me-a-coffee. Thanks.